One of my primary goals at Argonne National Lab was to effectively
scale GPU enabled MPI code on the lab's supercomputers. I worked
primarily on two machines: Polaris, a petascale NVIDIA machine; and
Aurora, an in-development exascale machine with Intel hardware.
Our code uses Python APIs to call CUDA and SYCL kernels.
Our code has an MPI driver that is hardware agnostic,
and uses different kernel methods for each backend. Maintaining
this modularity was often challenging as the Python HPC
libraries are very much still in development, and the limited
availability of CPU simulators for all hardware backends
required attention to detail with our CI testing.
In order to achieve good scaling I minimized the amount of data
transfer between the GPU and CPU, and manually divided the work
assigned to each MPI rank among several GPUs. Using Python allowed
for relatively quick development and easy integration with the
scientific modeling work being done by my theoretical physicist
coworkers, but had the downside of severe overheads for more than
about 10,000 MPI ranks. Assigning multiple GPUs to each MPI rank
was key to accessing the full power of the lab super computers.
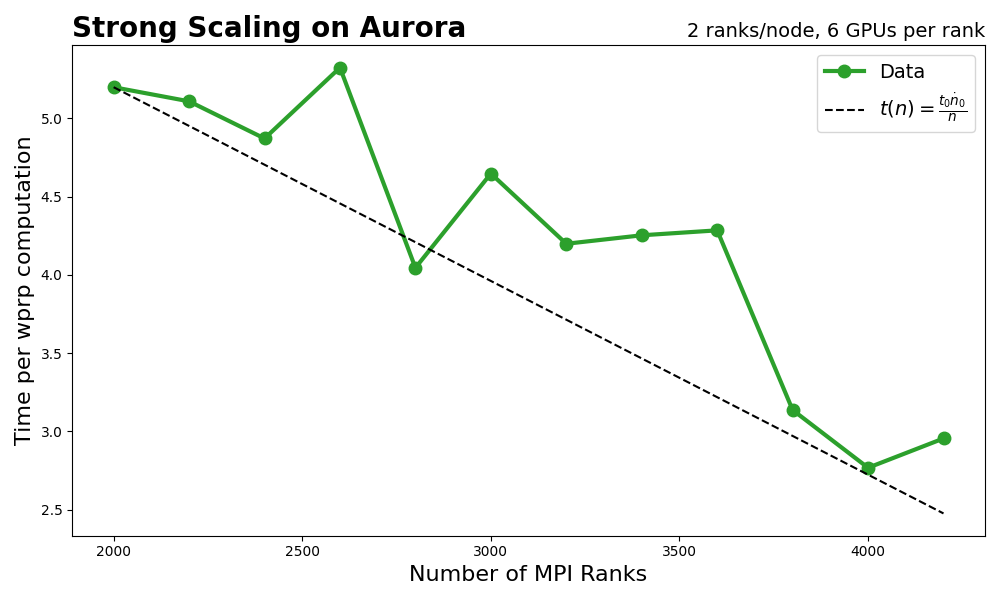
The below figure illustrates strong scaling performance on
2100 nodes of Aurora, equalling 4200 MPI ranks and 12,600 GPUs.
This work was done on a pre-production supercomputer with early
versions of the Aurora software development kit. Given the
strong scaling performance our code demonstates, the team will
be able to receive an early science allocation for compute time
in the near future.